
Parto dalla fine, era da un po di tempo che volevo fare qualche articolo su questo splendido strumento che è Notepad++, per me amico inseparabile direi da 20 anni. Facendo le ricerche per questo articolo ho scoperto che in realtà è stato pubblicato per la prima volta nel 2003, quindi 17 anni fa .. insomma sarò stato tra gli early adopter perché veramente mi sembra di averlo sempre usato. Parto dalla fine perché parto da una cosa molto complicata da fare con Notepad++ mentre mi ero ripromesso di scrivere altri articoli in quest’ordine:
1- Utilizzare Notepad++ per visualizzare i caratteri nascosti e utilizzarli per fare delle ricerche e delle sostituzioni ed altri trucchetti;
2- Utilizzare Notepad++ con le Regular Expression (RegEx) per fare ricerche;
3- Utilizzare Notepad++ con le Regular Expression (RegEx) per fare sostituzioni;
4- Utilizzare Notepad++ con le Regular Expression (RegEx) per fare sostituzioni avanzate.
Bene, questa è la 4 e le altre 3 le farò se ne sentirete il bisogno, chiedete quindi quello di vostro interesse.
Trovate Notepad++ qui, è un software free, distribuito sia a 32 che a 64 bit. Personalmente preferisco la versione a 32bit solo perché un plug-in che spesso uso (TextFx) è disponibile solo per la 32bit e non ho trovato ancora niente che possa sostituirlo nei plugin a 64bit (in realtà non ho cercato molto).
DISCALMER ! Non sono un esperto di Notepad++, quindi ben vengano tutti i consigli di chi lo conosce meglio di me!
Ho conosciuto la prima volta le espressioni regolari o regular expression o RegEx nel 1999. Da allora le uso saltuariamente quindi tutte le volte i primi minuti sono un patimento però ne vale sempre la pena, altrimenti ci sarebbero cose impossibili da fare.
Tutto nasce dal dover lavorare con dei file .CSV (comma-separated values) un tipo di file che viene molto utilizzato per gestire dati ed informazioni, come input od output di database o come interscambio tra applicazioni (pensiamo a Dynamo per Revit). Non tutti hanno bene in mente che tipo di file deve essere ne come dovrebbe essere fatto bene e quindi succede, come oggi, che mi trovo a dover gestire un .csv di 168.086 (si centosessantottomilaottantasei) righe con dei campi che mi creano problemi.
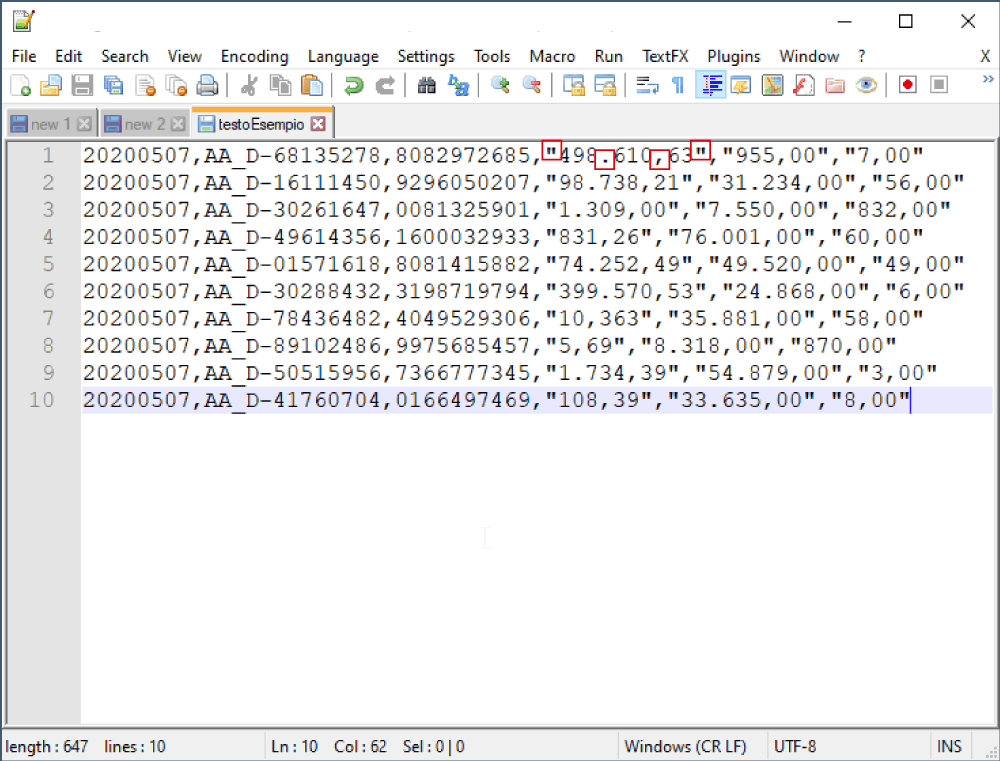
Il problema è che il file, composto da campi delimitati da virgole, ha le ultime tre “colonne” di dati formattate con dei doppi apici per racchiudere il valore, il punto per delimitare le migliaia e la virgola per delimitare i decimali. Nonostante il file non fosse del tutto sbagliato (io avrei omesso il punto delle migliaia), non era conforme a quello che dovevo fare. Avevo quindi la necessità di trovare un modo veloce e sicuro per ripulire 504.258 stringhe del documento.
Con la funzione ricerca e sostituisci (Find & Replace) sarebbe stato difficile far capire quale era il punto da togliere, sostituire una virgola specifica con un punto e togliere anche gli apici, ma Notepad++, oltre alla ricerca e sostituzione normal ha anche quella basata su Regular expression che andremo ad utilizzare.
Adesso c’è da capire cosa sono le Regular expression, chiamate anche RegEx e come si usano.
Per fare quello che ci serve non abbiamo bisogno di molte conoscenze, ma se volete approfondire potete partire da qui (o cercare con google).
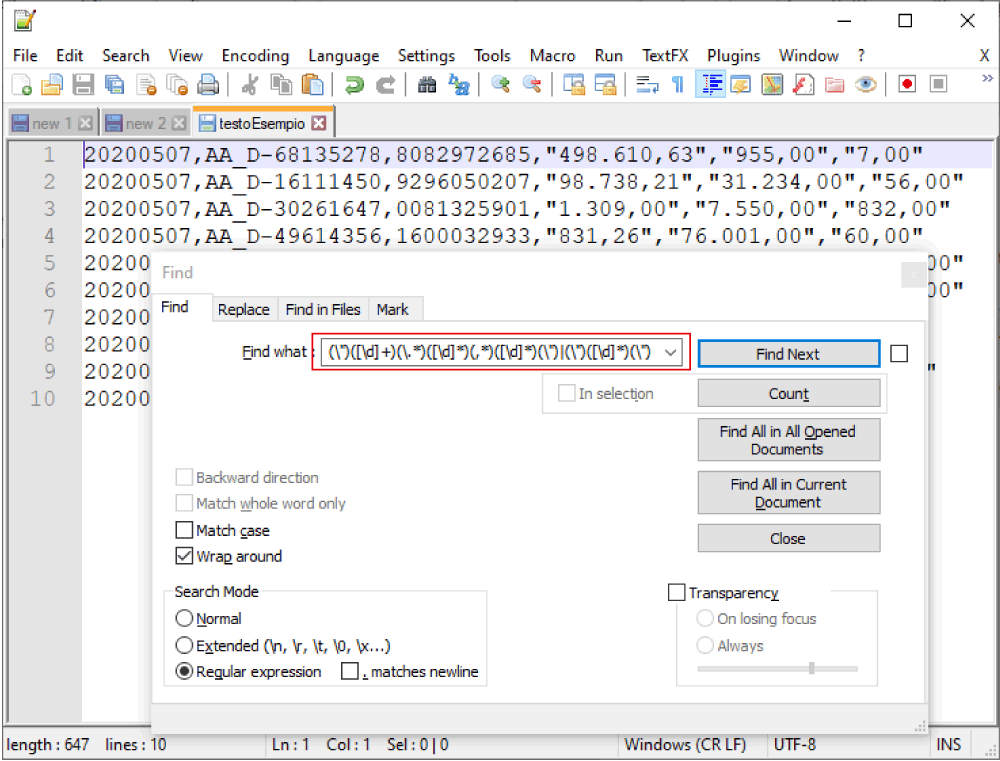
Quello che ho usato è la seguente stringa di ricerca
(\”)([\d]+)(\.*)([\d]*)(,*)([\d]*)(\”)|(\”)([\d]*)(\”)
Potevo anche scrivere \”[\d]+\.*[\d]*,*[\d]*\”|\”[\d]*\” senza le parentesi tonde, ma come vedremo dopo, le parentesi ci serviranno (in realtà potevo anche scrivere \”[\d]+\.*[\d]*,*[\d]*\”, la parte |\”[\d]*\” è un refuso).
Analizziamo meglio la stringa :
\“[\d]+\.*[\d]*,*[\d]*\“|\“[\d]*\“
Il backslash \ si chiama carattere di escape serve per dire al programma che quello che viene dopo (come le doppie virgole e il punto) deve essere interpretato letteralmente e non come comando.
Tutto quello che si trova all’interno delle parentesi quadre [ ] è un pattern da ricercare, in questo caso il pattern è \d che significa digit, cioè qualsiasi numero (potete trovarlo anche come [0-9]). Il + che segue significa che tutto quello che è tra le parentesi quadre deve essere presente una o più volte.
Troviamo poi il \. che letteralmente significa che dopo uno o più numeri, ci deve essere un . (punto) e l’asterisco * subito dopo specifica che il punto può esserci zero o più volte (la differenza tra + e * è che mentre per il + il pattern deve essere presente almeno una volta, per * è facoltativo che quel pattern di riferimento sia presente anche solo una volta). Ripetiamo la stessa cosa [\d]*. La , (virgola) che segue è un carattere e * subito dopo significa che può essere presente zero o più volte (in realtà ci sarebbero modi più raffinati di gestirlo, ma per questo esempio va più che bene). Ancora una volta la possibilità di una serie di numeri ripetuti [\d]* e per finire tutto questo pattern deve terminare con un doppio apice \“.
Il simbolo | indica che uno dei due pattern quello a destra e quello a sinistra deve essere trovato, in informatica è quello che si chiama OR booleano, per tradurre in questo caso è un alternatore (alternator).
La parte che segue è una semplificazione, senza punti e senza virgole, ma in realtà è alquanto inutile per questo esempio.
Veniamo però alla versione completa, quella con le parentesi:
(\“)([\d]+)(\.*)([\d]*)(,*)([\d]*)(\“)|(\“)([\d]*)(\“)
Le parentesi servono per raggruppare, abbiamo quindi 10 gruppi differenti che formano il pattern della nostra RegEx (vederemo tra poco il perché).

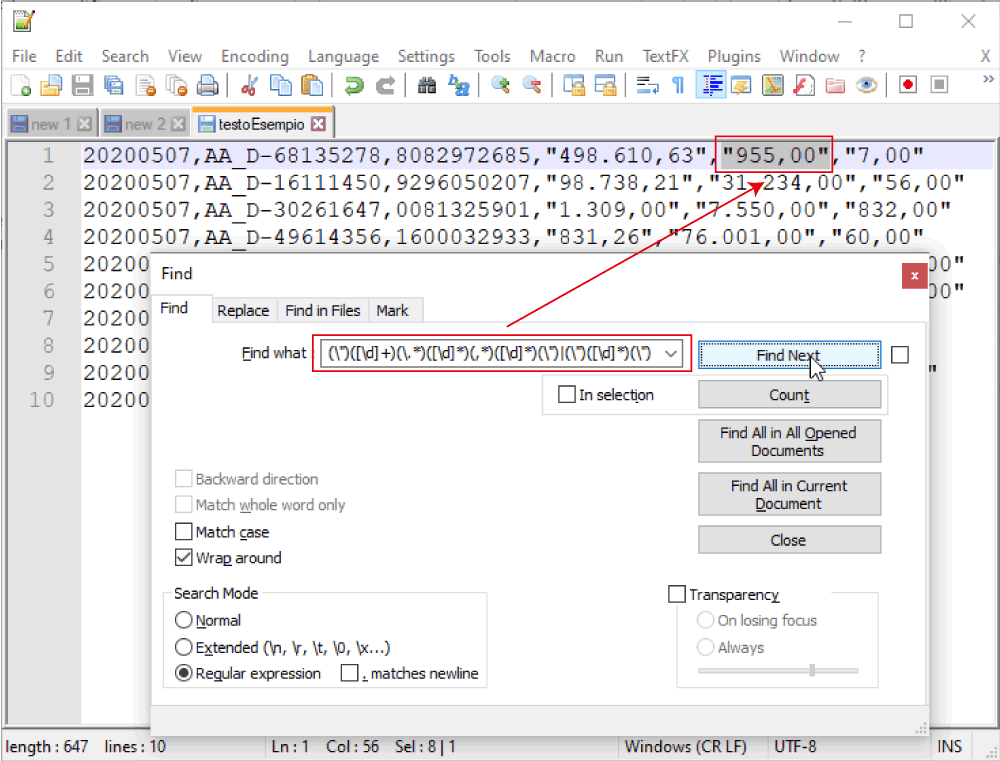
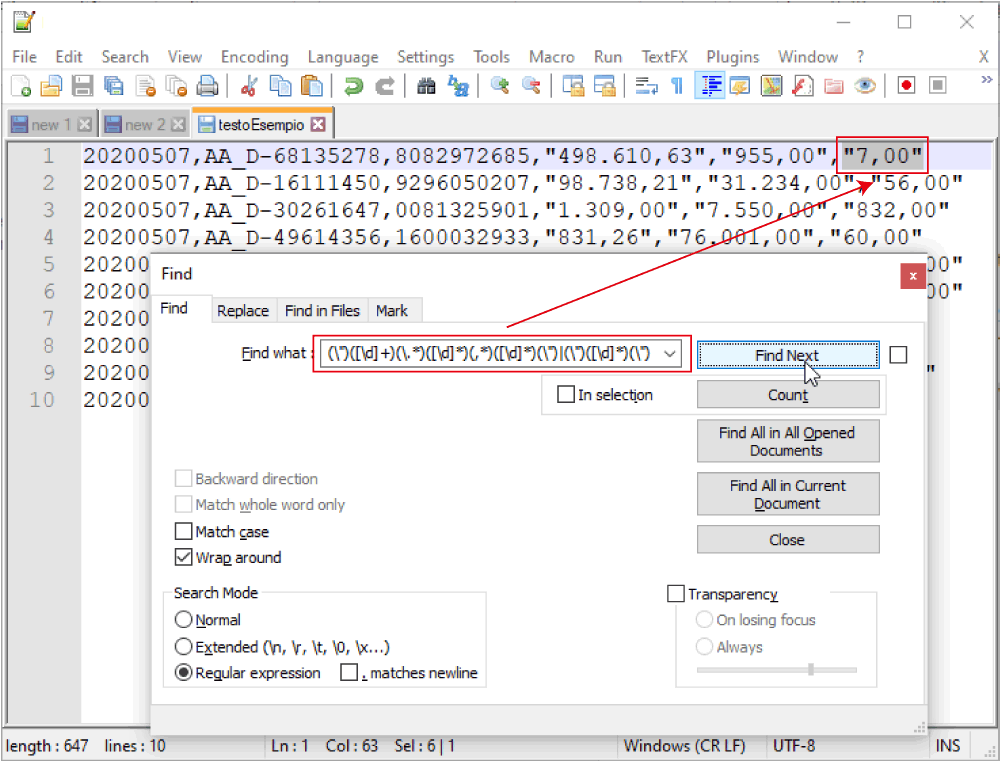
Se proviamo, questa RegEx, riesce a selezionare tutti i campi che ci interessava selezionare che abbiamo nel .csv .
Noi però volevamo sostituire, cancellare, modificare queste stringhe, e non solo selezionarle. Per intenderci vogliamo che:
“498.610,63”,”955,00″,”7,00″ diventi 498610.63,955.00,7.00 e lo vogliamo fare per 168.086 righe.
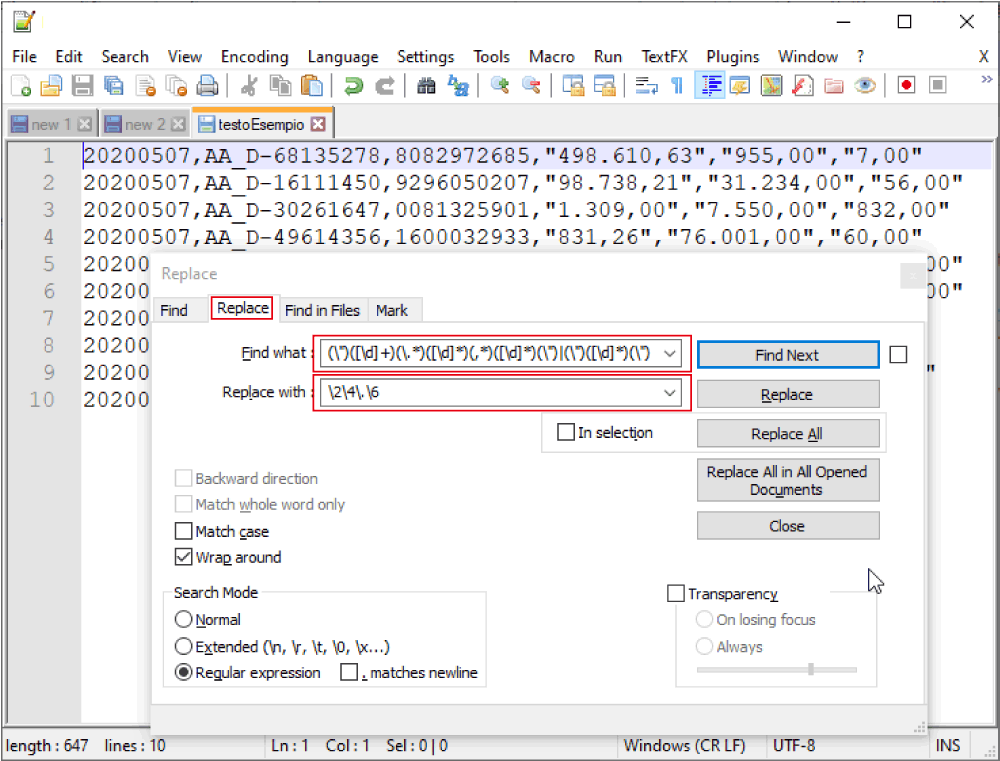
Ci spostiamo quindi sulla tab Replace e nel campo “replace with:” inseriamo ancora una RegEx.
\2\4\.\6

Questo è quello che succede mettendo le parentesi per creare dei gruppi, in realtà abbiamo detto al programma che il nostro pattern, è diviso in 10 gruppi differenti.
I gruppi vengono gestiti con il backslash ed un numero progressivo, da 1 che è il primo gruppo a n, in questo caso 10.
Se la nostra necessità era solo selezionare tutto il pattern “498.610,63” per contare quanti erano o per cancellarli, fare i gruppi non avrebbe aiutato in nessun senso.
Così facendo però abbiamo preso un maggior controllo su quello che viene dopo la selezione, che è la sostituzione.
Infatti con la RegEx \2\4\.\6 diciamo al programma che della selezione appena fatta vogliamo tenere solo il gruppo 2, il gruppo 4 mettere un . (punto) e tenere il gruppo 6.
Quello che succede è questo:
- \1 (gruppo 1) – i doppi apici vengono eliminati;
- \2 (gruppo 2) – uno o più numeri saranno tenuti;
- \3 (gruppo 3) – il punto (che ci sia o meno) andrà eliminato;
- \4 (gruppo 4) – altri numeri, se ci sono saranno tenuti;
- \5 (gruppo 5) – la virgola sarà eliminata;
- . – andrà inserito un punto tra il gruppo 4 ed il 6
- \6 (gruppo 6) – altri numeri dopo la virgola, se ci sono andranno tenuti;
- \7 (gruppo 7) – gli apici di chiusura saranno eliminati;
- \8 \9 \10 – in questo caso sono superflui e saranno cancellati.
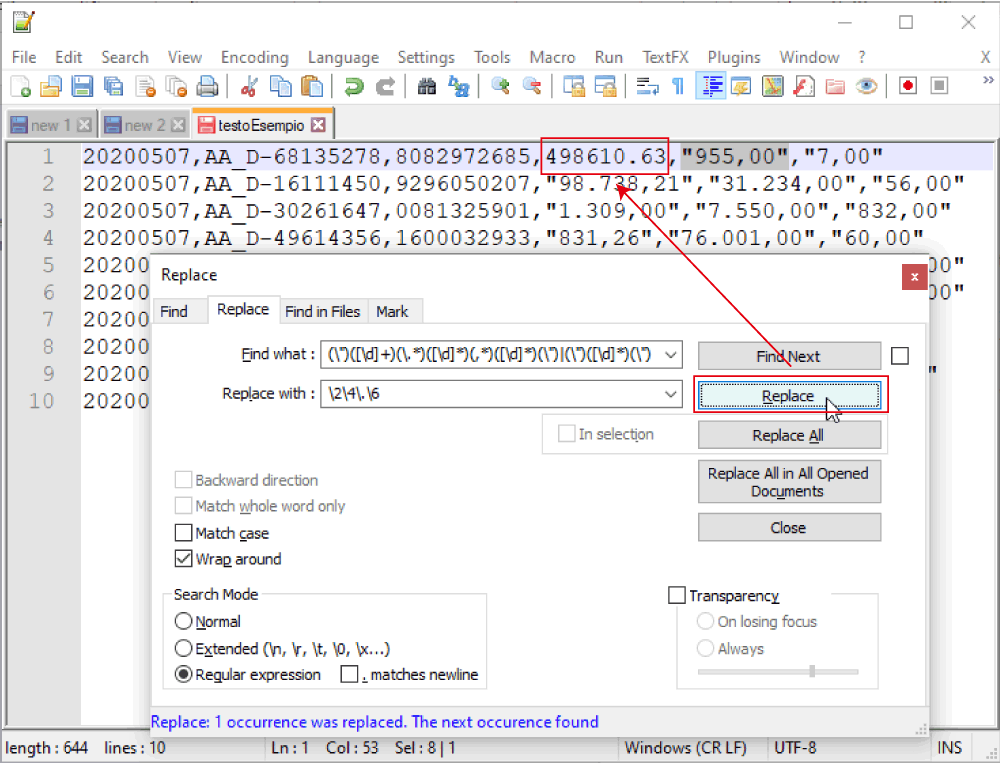
Cliccando su “Replace” verrà selezionato e sostituito il primo pattern trovato.
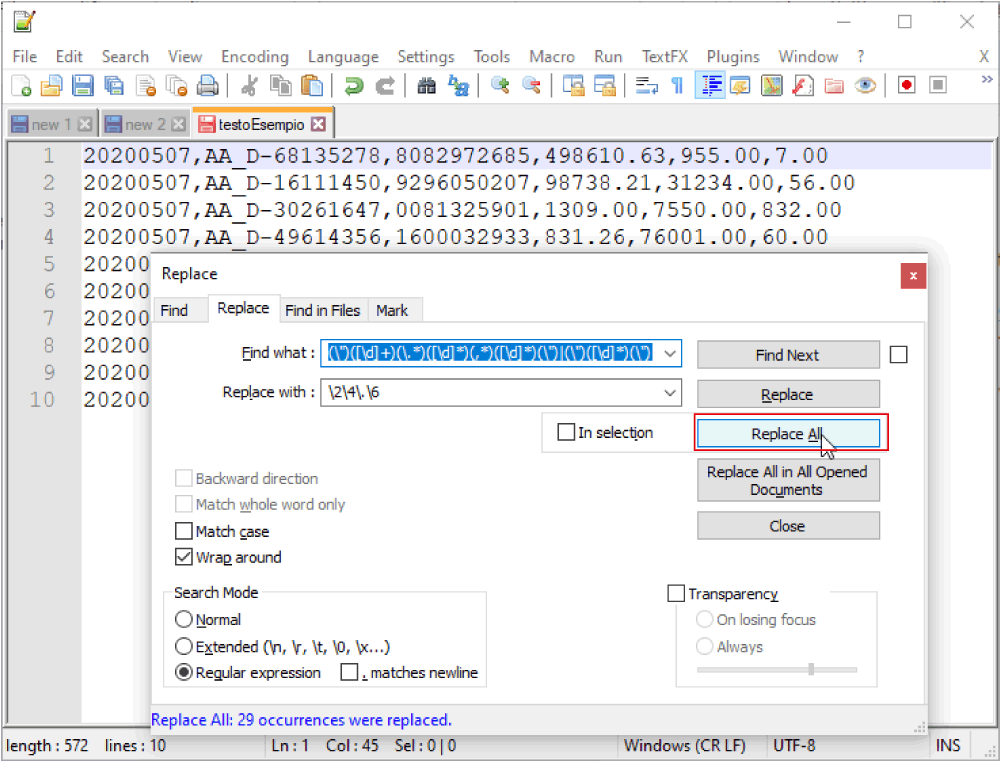
Cliccando su “Replace All”, verranno sostituiti tutti i pattern del documento (come vediamo in basso, in questo caso solo 29, ma nel documento originale (che per inciso assomigliava abbastanza a questo come impostazione) erano 504.258, e nonostante tutto ci sono voluti alcuni secondi.
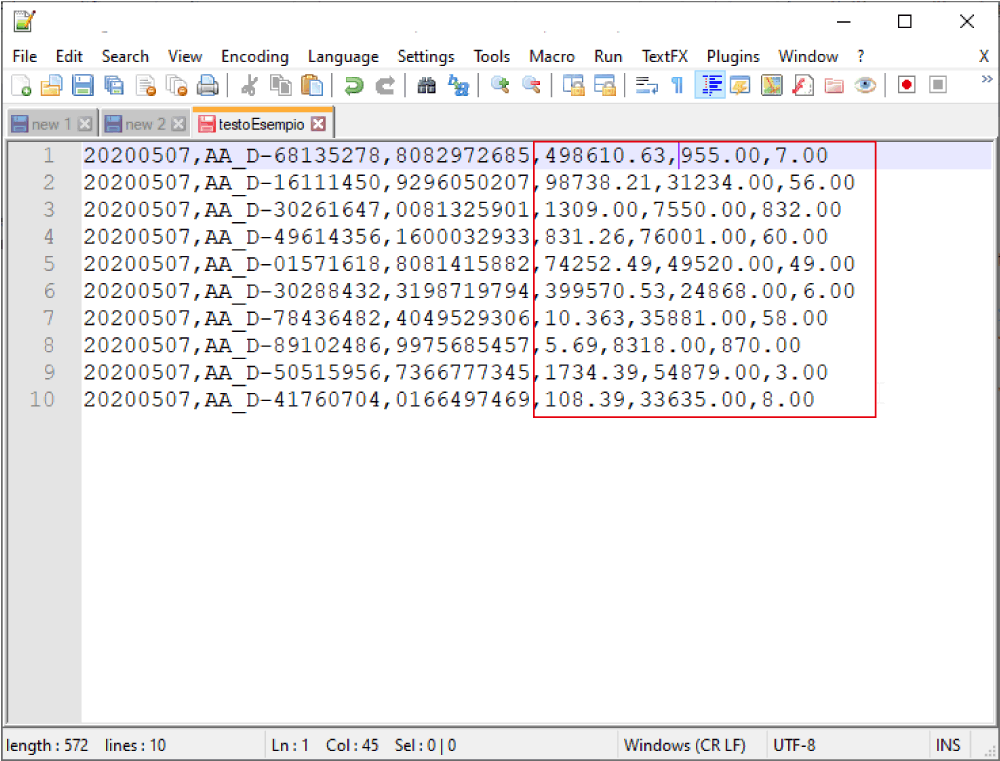
Il risultato è il nostro file pulito, in modo automatico, senza possibilità di errori.
Le espressioni regolari, regular expression, sono una delle più potenti armi che abbiamo per lavorare con i testi. Andrebbero insegnate a scuola!
Grazie per aver avuto la pazienza di leggere fino in fondo.



